Kosmos 2 è un Large Language model multimodale che introduce, rispetto al suo predecessore (Kosmos1) la possibilità di fare il grounding tra il testo e l’immagine. Questo permette al modello di espletare una serie di task molto variegate come il “phrase grounding” (data una frase trova le entità di cui si parla nell’immagine), l’ “image captioning” (data un immagine genera una descrizione testuale della stessa) ed altre. Nell’ambito del Progetto che abbiamo introdotto precedentemente questo permetterebbe non solo di sviluppare un sistema software che è in grado di individuare oggetti negli ambienti, ma anche di rispondere a domande sugli stessi, fornire una descrizione degli ambienti, e in generale, di espletare al meglio le sue funzioni.
Grit: unlocking grounding in KOSMOS
La possibilità di fare grounding è stata “sbloccata” in kosmos, introducendo un nuovo dataset su cui viene addestrato il modello: Grit.
Grit è un dataset pubblico composto da “Grounded image Text pairs”, cioè da coppie di immagini e testo grounded. Nel pratico questo significa che ad ogni token corrisponde un’immagine ed un testo grounded. Questo significa che gli autori di kosmos hanno preso immagini, con una caption già pronta, (presi da altri datasets) ed hanno convertito la caption in una grounded description, cioè un testo che facesse riferimento al suo interno ai bounding box corrispondenti alle entità. Ecco un esempio di grounded text description di kosmos (che nel paper viene chiamato hyperlink):

In questa descrizione c’è l’embedding dell’immagine, il bounding box corrispondente ad “It” e il bounding box corrispondente a “campfire”. Per arrivare a questo da una coppia (immagine,descrizione) il processo è quello sintetizzato qui sotto:

Il processo è diviso in due parti, più l’unione del risultato di ogni parte:
- Parte1: genera “noun chunk- bounding box” pairs, cioè coppie di entità e le boounding boxes corrispondenti
- Parte2: genera “referring expressions”
- Unione: viene generato un “referring expression- bounding box” pair
Parte 1:
L’obiettivo è generare coppie di “nome-bounding box”

- si identificano i nomi
- vengono identificati sull’immagine
- vengono creati i bounding box e associati ai nomi delle entità
Parte 2:
l’obiettivo è capire, attraverso l’utilizzo di un parsing tree quale è la referring expression:
- espandere i nomi:
esempio: supponiamo la caption sia “a dog in a field of flowers”, i nomi sono “dog”,“field”,“flowers”
- flowers rimaner “flowers”
- field diventa “a field of flowers” essendo flowers complemento di field
- dog diventa “a dog in a field of flowers” essendo “field of flowers” complemento di luogo di dog. risulta quindi “a dog in a field of flowers” essere la referring expression
A questo punto, quindi la referring expression viene unita al bounding box di dog (soggetto della referring expression)

Da coppie (expression, bounding box) agli hyperlink:
Il risultato è quindi quello di una serie di coppie “referring expression - bounding box”, ma ancora non è finita: dobbiamo trasformare ancora le referring expression+ bounding box in hyperlink.
 La funzione dell’hyperlink è quella di creare un effettivo collegamento tra lo span testuale e l’immagine vera e propria, e sono proprio il cuore dell’abilità di grounding del modello.
Sostanzialmente al text span vengono aggiunti:
La funzione dell’hyperlink è quella di creare un effettivo collegamento tra lo span testuale e l’immagine vera e propria, e sono proprio il cuore dell’abilità di grounding del modello.
Sostanzialmente al text span vengono aggiunti:
- l’embedding dell’immagine
- i riferimenti ai bounding box per le entità a cui bisogna far corrispondere un bounding box.
Nota: negli hyperlink le bounding box non sono specificate con una sintassi classica ma vengono convertiti in “location tokens” come si evince dall’immagine sopra.
Evalutation
Il modello è stato valutato su più tasks, ne vedremo alcune: quelle essenziali al nostro progetto, per le altre, si rimanda al paper di kosmos2
Phrase grounding:
Chiediamo al modello di predire un insieme di bounding boxes dato un insieme di frasi
Input: immagine e prompt prompt: “<gounding>A man in a blue hard hat and an <p> orange safety vest</p>”
 Il bounding box viene confrontato con quello di Grit usando IOU = intersection over union.
Sostanzialmente se i due bounding box sono sovrapposti per più della metà il grounding viene considerato corretto.
Il bounding box viene confrontato con quello di Grit usando IOU = intersection over union.
Sostanzialmente se i due bounding box sono sovrapposti per più della metà il grounding viene considerato corretto.
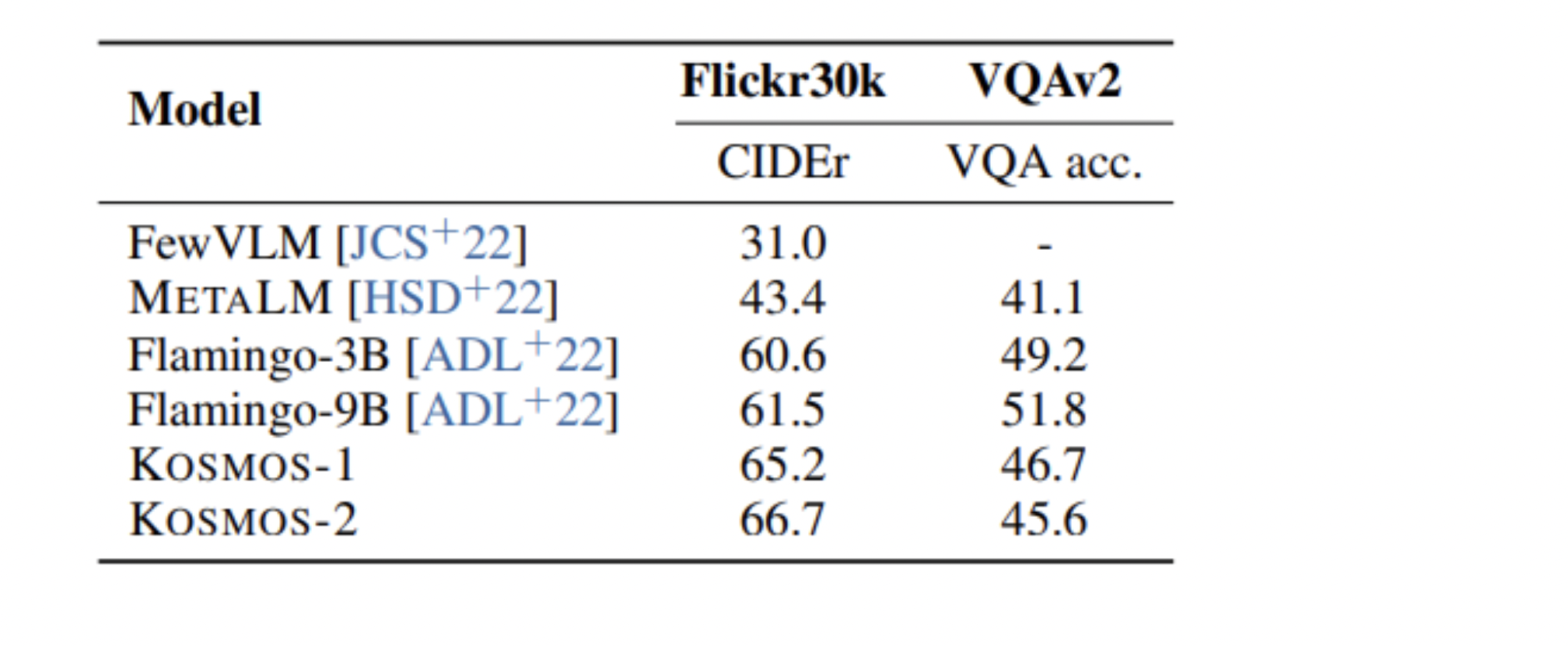
 Questi sono risultati mostrati per la task di phrase grounding. Come si può vedere viene evidenziata un’ottima performance zero-shot.
Questi sono risultati mostrati per la task di phrase grounding. Come si può vedere viene evidenziata un’ottima performance zero-shot.
Referring expression generation:
Il task consiste nel: data un’immagine ed uno o più bounding boxes, generare una descrizione delle entità che appaiono nella bounding box.
Input: immagine + bounding box output: descrizione delle entità evidenziate
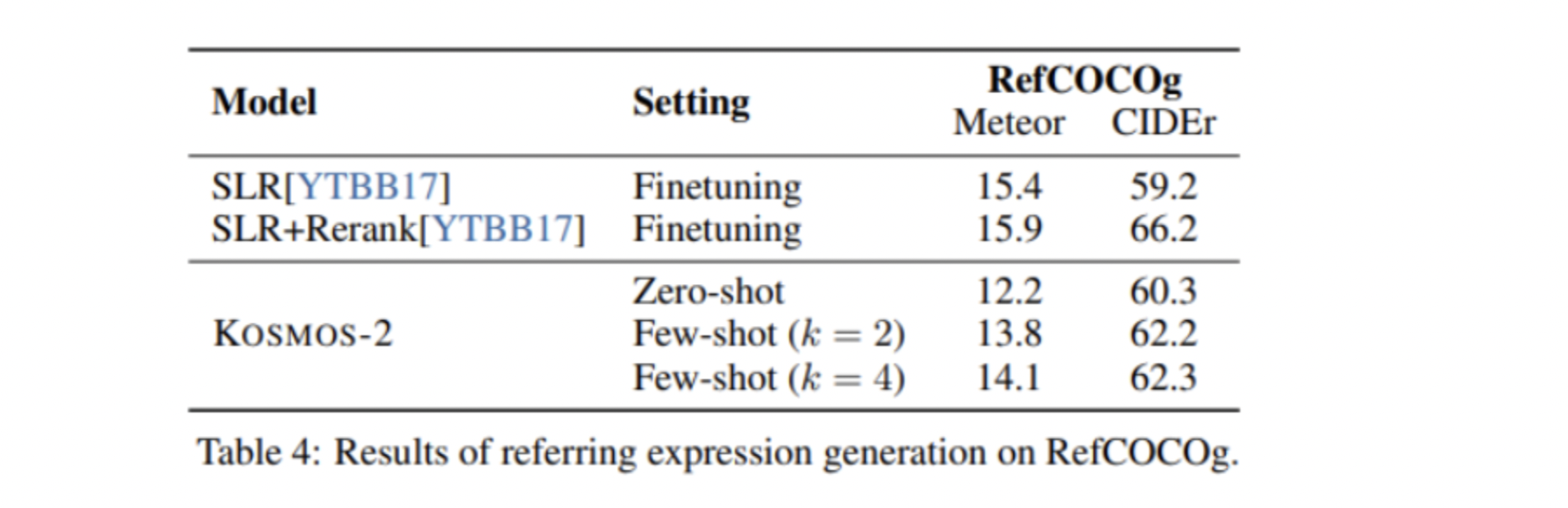
Image captioning
Task: data un’immagine generare una grounded description della stessa
input: immagine output: grounded description
Risultati: